索引
数据库中排好序的数据结构,以协助快速查询、更新数据库表中数据。
磁盘存取原理
- 寻道时间:
速度慢、费时,旋转时间:速度较快。因此要减少查找次数,节点大小为block的整数倍。 - 系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
-
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like 'innodb_page_size';
底层数据结构
平衡二叉树(AVL Tree)
符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。
B-Tree(平衡多路查找树)
- 度(Degree):节点的数据存储个数可变;
- 节点中数据key从左到右递增排列。
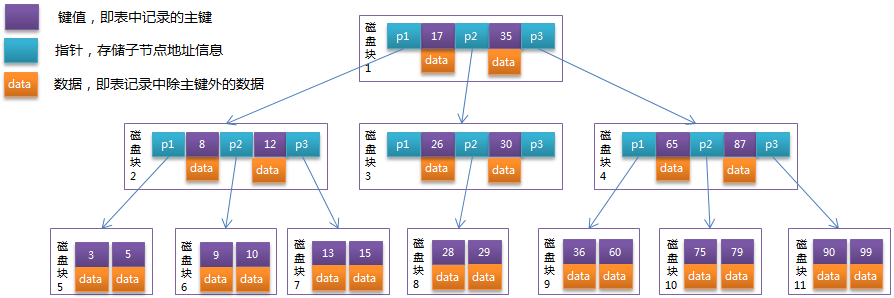
B+Tree索引(InnoDB存储引擎)
- 非叶子节点只存储键值信息;
- 所有叶子节点之间都有双向指针(适合范围查找),构成链式环状结构;
- 数据都存放在叶子节点中。
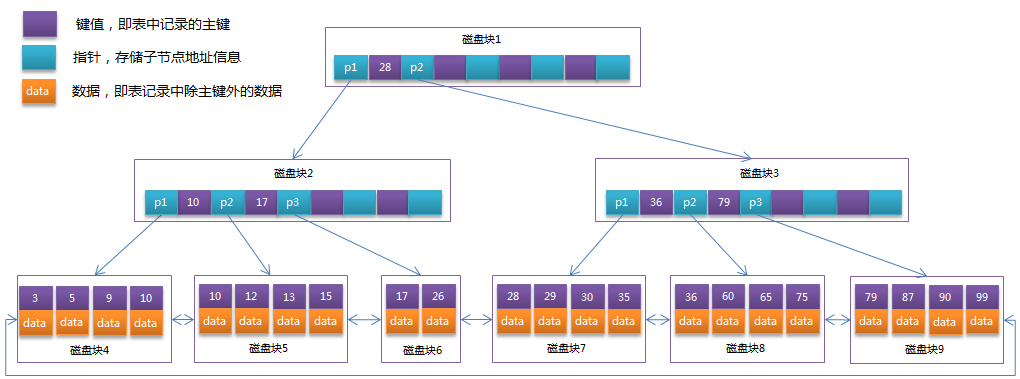
聚集索引(clustered index)与辅助索引(secondary index)
- 上图为聚集索引(又称主键索引),叶子节点存放整张表的行记录数据;
- 辅助索引叶子节点只存索引和相应的聚集索引,即主键(节省空间,数据一致性便于维护)。
- 当使用辅助索引查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
联合索引
- 索引最左前缀原理:只有首列索引存在查询条件中才会走索引。
覆盖索引
- 即在辅助索引就可以查到记录,而不需要查询聚集索引中的记录。
Explain
explain extended
会在explain基础上额外提供一些查询优化的信息。可紧跟其后通过show warnings命令得到优化后的语句(优化器处理)。
mysql> explain select * from XX;
XX
mysql> show warnings;
XX
explain partitions
如果查询基于分区表,会显示查询将要访问的分区。
explain中的列
-
id列:select的序列号,id顺序按select出现的顺序增长,id越大执行优先级越高,相同则从上往下执行,id为NULL最后执行。MySQL将查询分为简单查询(simple)和复杂查询(primary:简单子查询、派生表(from语句中的子查询)、union查询)。 -
select_type列
- simple:简单查询,查询不包含子查询和union。
- primary:复杂查询最外层的select。
- derived(派生、衍生):包含在from子句中的子查询。MySQL会将结果存放在一个临时表(派生表)中。
- union:在union中的第二个和随后的select。
- union result:从union临时表检索结果的select。
explain select 1 union all select 1;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | UNION | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
-
table列:explain的行正在访问的表。
- from子句中有子查询时,table列是
<derivenN>格式,表示当前查询依赖id=N的查询,于是先执行id=N的查询。 - union时,union result的table列为<union1,2>,1和2表示参与union的select行id。
- from子句中有子查询时,table列是
-
type列:表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。- 依次最优->最差:system>const>eq_ref>ref>range>index>ALL;一般来说得保证查询达到range,最好ref;
- type列为NULL时,优化器可优化,单独查找索引完成,不需要执行时访问表。
- const,system:对查询的某部分进行优化并将其转化成一个常量(可以看成show warnnings的结果)。用于主键或唯一索引的列与常数比较时,表最多匹配一行。system是const的特例,表只有一条元组匹配时为system。
- eq_ref:主键或唯一索引的字段被连接使用,最多只返回一条符合条件的记录。
- ref:相比eq_ref,不使用唯一索引,而使用普通索引或者唯一性索引的部分前缀,索引要和某个值比较,可能找到多行。
- range:范围扫描通常出现在in(),between,<,>,=等操作中。使用索引检索给定范围的行。
- index:扫描全表索引,通常比ALL快一些。(index从索引中读,ALL从硬盘中读取)。
- ALL:全表扫描,从头到尾查找所有行,通常需要增加索引优化。
-
possible_keys:显示查询可能使用哪些索引来查找。为NULL时,表示表中数据不多,优化器认为索引对查询帮助不大,选择全变查询。
-
key列:显示实际采用的索引查表,没有则为NULL。如果想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用force index、ignore index。 -
key_len列:显示索引使用的字节数。
-
ref列:显示key列记录的索引中,表查找值所用到的列或常量;常见的有:const,字段名。
-
rows列:估计MySQL要读取并检测的行数,不是结果集中的行数。 -
Extra列:展示额外信息,常见重要信息有:- Using index:查询的列被索引覆盖,并where条件列是
索引的前导列,高性能的表现。一般使用了覆盖索引。 - Using where:查询的列未被索引覆盖,where筛选条件非索引的前导列。
- Using where Using index:查询的列被索引覆盖,并且
where筛选条件是索引列之一但是不是前导列。意味着无法直接通过索引查找来过滤出数据。 - NULL:查询的列未被索引覆盖,where筛选是索引前导列,用到了索引但并非所有字段被覆盖,必须通过“回表”来实现,不是纯粹用到了索引,也并非完全没用。
- Using index condition:与Using where类似,查询的列不完全被索引覆盖,where条件是一个前导索引。
- Using temporary:需要创建一张临时表来处理查询。一般要优化!
- Using filesort:对结果会使用一个外部索引排序,而非按索引次序从表里读取行。需要优化!
- Using index:查询的列被索引覆盖,并where条件列是
索引最佳实践
- 全值匹配;
- 最佳左前缀法则;
- 不在索引列上做任何操作(计算、函数、(自动或手动)类型转换),会导致索引时效而全表扫描;
- 存储引擎不能使用索引中范围条件右边的列;(Using index condition);
- 尽量使用覆盖索引(只访问索引查询(索引列包含查询列)),减少select *语句;
- 尽量避免使用不等于(!=或<>),因为使用时会无法使用索引导致全表扫描;
- is null,is not null也无法使用索引;
- like以通配符开头(’%XX’)MySQL索引会失效;
- 字符串不加单引号索引时效;
- 少用or,用它连接时很多情况下索引会失效。
总结:假设index(a,b,c)
| Where语句 | 索引是否被使用 |
|---|---|
| where a=3 | Y,使用到a |
| where a=3 and b=4 | Y,使用到a,b |
| where a=3 and b=4 and c=5 | Y,使用到a,b,c |
| where b=3 或者 where b=4 and c=5 或者 where c=4 | N |
| where a=3 and c=5 | 使用到a,但是C不行,b中间断了 |
| where a=3 and b>4 and c=5 | 使用到a和b; c不能用在范围之后,b断了 |
| where a=3 and b like ‘kk%’ and c=4 | Y,使用了a,b,c |
| where a=3 and b like ‘%kk’ and c=4 | Y,只是用了a |
| where a=3 and b like ‘%kk%’ and c=4 | Y,只是用了a |
| where a=3 and b like ‘k%k%’ and c=4 | Y,使用了a,b,c |
like ‘kk%’=const,’%kk’和’%kk%’想当于范围